今天我想简单介绍一下我们在Neurips 2022 (2022 Conference on Neural Information Processing Systems) 中的一篇小样本学习 (图像分类) 的工作: FewTure-Rethinking Generalization in Few-Shot Classification。总的来说,这篇工作与之前小样本图像分类最大的区别在于完全采用 Transformer (ViTs, Swin) 作为backbone进行图像编码和纯无监督学习 (unsupervised) 进行预训练。当然,采用Transformer和无监督学习并不是我们的主要动机 。接下来我们就来详细讨论下这样做是出于什么原因 (motivation) 和带来了哪些提升 (improvement)。
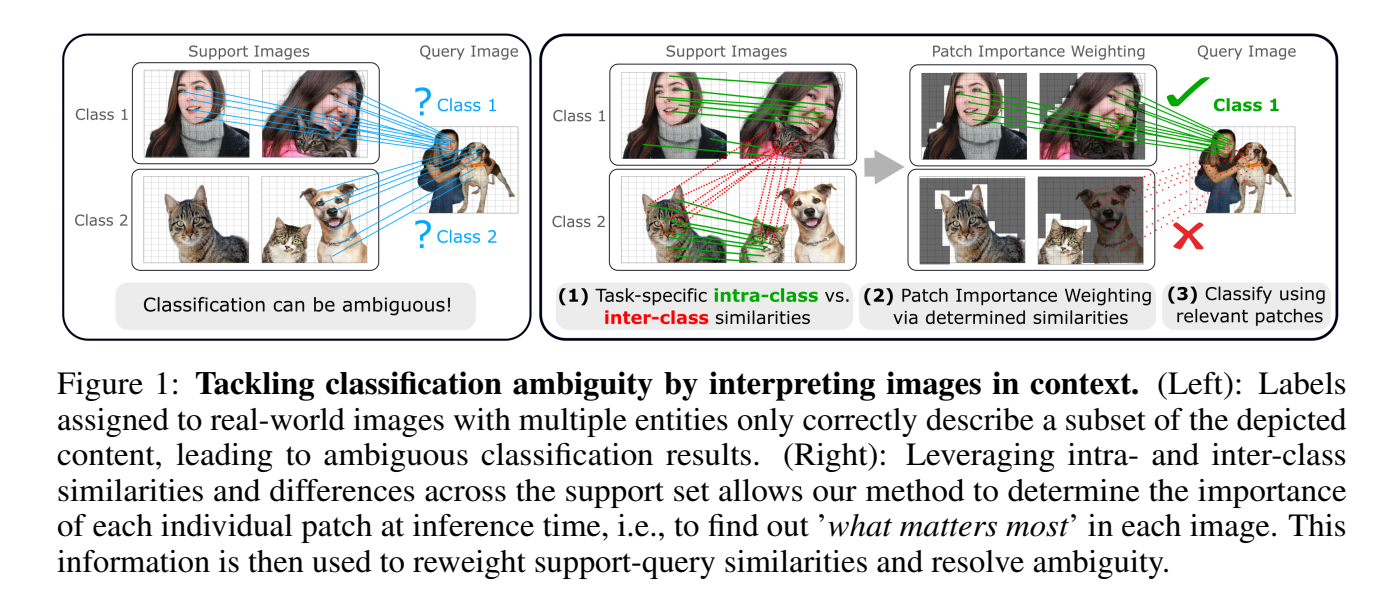
Figure 1. Conceptual Diagram
小样本学习的新引擎
小样本学习领域 (图像分类) 从2019年开始迎来了百花齐放的纪元,其中涌现出很多杰出的工作, 例如 DeepEMD, FEAT, CTX, CAN, DSN, etc 诸多颇具影响力的工作。 这些工作大多基于ResNet的变体 (ResNet-12/ResNet-18) 进行图像编码。还有些工作,例如 FEAT 还采用了 WRN-28-10作为encoder。总的来说ResNet的变体会优于WRN因为越大的backbone更容易在小数据(training set)上面overfit,进而导致不能泛化在测试集上。尽管ResNet相对于WRN有着更好的泛化性,但是仍然存在着相当多的问题。然而,如果我们深入挖掘其中的原因,我们可以发现两个很明显不能泛化的原因: Supervision collapse: 在CTX 中着重描述, 和 Label confusion: 在 CAN 中有描述。接下来我们將这两点作为我们工作的主要动机进来详细的讨论。
动机
Supervision collapse: 监督坍塌
Supervision collapse总的来说是模型不能泛化在测试集,而坍塌 (过拟合overfit)在某一训练集类别 (class)特征 (features)上的一种具体的表现。CTX文章着重讨论了此问题,我们来举实例就行说明:

CTX
首先用ProtoNet在Meta-Dataset进行监督训练 supervised training (CTX为纯episodic training 无pretraining),然后在Meta-Dataset中ImageNet的测试集中选取一张query image,之后在feature space中选取top 9 nearest-neighbor (这里面包含训练集和测试集的instance)。 从上图我们清晰的可以发现,每张query 的top 9 包含了大量错误训练集的instance,其中大部分是相同错误的Class。这就说明我们的模型提取的特征坍塌在某一训练类别的特征上,从而无法泛化到测试集。
Label Confusion
接下来我们看一个更有趣的问题:label confusion

Label Confusion
首先想问大家一个问题,上方图片作为人类的我们会识别成什么类别?我个人第一眼看上去会识别成人类 human这个类别。然后此图作为Mini-ImageNet的一个类别为: curtain。这就很荒谬,一张图60%的内容为人类,最后label居然是窗帘。此过程会导致一个结果:监督预训练过程中模型只关注curtain的feature,而忽略图中大部分人类的feature。我们怀疑此过程是导致监督坍塌supervision collapse 的一个重要原因,因为小样本学习的训练集和测试是完全不同的class,在训练过程中忽略大部分的feature (设想这些被忽略的feature出现在某些测试类别上) 会导致模型学习不到更泛化更多样的特征,进而过拟合到训练集上。至此,单label的annotation对于小样本学习来说是致命性的。综上是我们这篇工作的主要动机,我们也是围绕着这两个问题展开讨论,提出结果方法的。接下来我着重介绍我们此工作是如何一步一步减轻上述问题。
解决方法
Transformer and Patch Tokens
如何能学习到更泛化的特征?回答此问题,我们得结合上文。我们希望模型能够学习到一张图片中所有主要的个体 entity 的特征。这就是说如果我们能给买个pixel进行Label的话,此问题就会解决,这也是instance segmentation的任务。但是分类和分割终究是两种任务。如何能最大限度的解决此问题?我们提出的解决方案是用 Vision Transformer。 原因是VIT可以将图片本地区域 local region,划分成相同大小的网格然后进行编码,这样很大几率每个local region都被一个主要个体占据,进一步来说这样做能将所有主要个体特征encoder (小几率出现一个本地区域出现两种个体的特征)。这就是我们使用VIT的主要动机。
Self-Supervised Pretraining: 自监督训练 前文我们讨论了监督学习,尤其是在预训练中会对模型造成伤害。在我们发先上述问题之后,我们提问:假如监督预训练不能泛化得很好,那么自监督学习呢?通过查阅文献,CTX 等相关工作提出,在监督学习中加入自监督学习的component会提升模型的泛化性, 例如CTX中的simclr 等等。当然还有很多小样本学习的工作引入了无监督学习和自监督学习的概念,但是这些工作基本上是在监督预训练的过程中加入了无/自监督学习作为辅助 auxiliary task。具体原因是因为,自监督学习可以explore图像中固有的特征,不局限在人类标注semantic label上面。在我们的工作中我们尝试假如预训练中完全不用监督学习会怎么样?是否能最大限度地试我们的模型学习到泛化的训练集特征?我们在后文中会用实验数据来进行证明 (此处强调一下,我们的工作预训练的过程中只有训练 集参与,例如Mini-ImageNet的训练集的64个class,因为之前看到有些工作在ImageNet上预训练,之后跑Mini-ImageNet。I mean, wtf ??? :))。
第二点,如上文所述,我们使用VIT (ViT small, Swin tiny)作为backbone。众所周知,ViT在小数据上不容易进行监督训练,因为缺少CNN的inductive bias,从而需要很大的数据量监督拟合。这就导致ViT在Mini-ImageNet这种小数据集上面超级容易过拟合。这也是我们采用自/无监督预训练的第二个原因。我们首先尝试了Dino,之后尝试了IBot,最后我们发现iBot的性能更好,当然这两种自监督学习都不是我们工作的贡献,就不这在里做多于赘述,感兴趣的朋友们可以详细阅读,实测有奇效。 接下来我们就来展示一下监督预训练和自/无监督预训练的区别。 再次强调我们只在训练集上预训练。
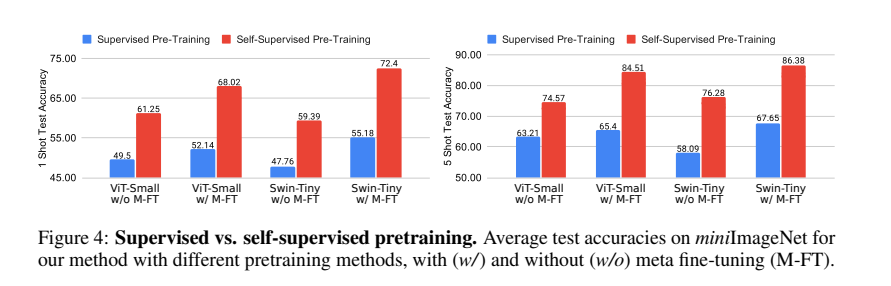
Supervised vs Unsupervised
我们对比一下只进行预训练之后在测试集上做evaluation (ViT w/o M-FT, M-FT在这里只meta fine tuning 也就是在训练集上面episodic training),我们可以看出不管是在1-shot还是在5-shot,同时不管是在ViT还是在Swin上面 supervised pretraining都被self-supervised pretraining完爆。这也证明了我们之前的猜测。
Learning token importance during inference:在推断的过程中学习哪个token/region更重要
上文我们论述了自/无监督预训练可以最大限度的学习到图像中所有的主要个体。但是对于小样本学习中的一个任务例如 5-way 5-shot task来说,有些特征很关键比如说foreground,有些不重要比如说background。如何能够使我们的模型只关注在重要的特征上?为解决此问题,我们的工作提出了token reweighting的机制:结合手头的任务信息,对每个token的重要性进行提炼。接下来我们我将介绍如何实现此机制。
首先我们把所有的support token提取出,然后用每个token和所有token做一个cosine similarity,这样能够找出相似的feature,比如说,不同狗的feature。为了避免每个token只学习到跟自己相近,进而忽略其他相同class的feature,我们将这个NXN的similar matrix进行diagonal blocking,从而解决上述问题 (详细工程操作请参考我们的论文)。这一步之后是最关键的一步:我们在这个被block的similarity matrix上面叠加上一组初始化为0的vector:v(此vector为token importance reweighing vector)。最后我们利用support image的label进行反向传播只更新vector v。此机制可以参考下图。
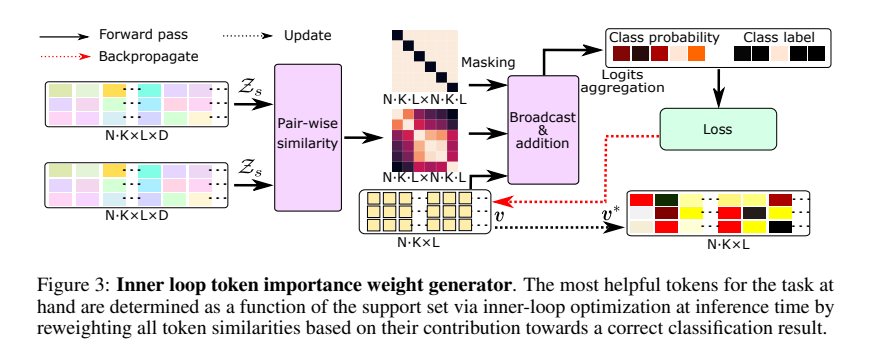
Inner Loop Optimization
这个vector v就代表我们每个support token的重要性 (对于当前任务,每个任务都会学习一组新的v)。接下来,当作query image的识别时,我们用query token和每个support token 进行pair-wise cosine similarity matching,之后再把这个 vector v 叠加再这个similarity matrix上,进一步告诉我们的模型哪一个support token 更重要!大致流程可以参考下图。朋友们如果感兴趣可以参考我们的论文,我这里讲的其实不是很详细。
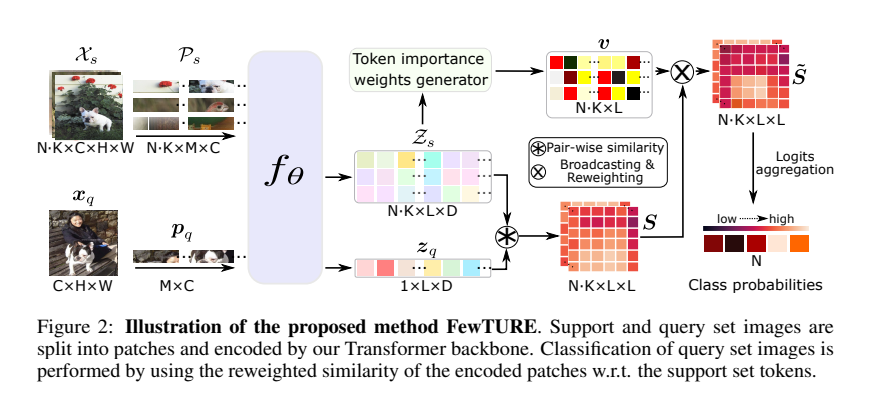
Framework
可视化展示
接下来我将展示这个vector v到底学习到了什么。

Visualization
大家应该不会感到意外吧?这一组图片是一个五分类任务中的几张图片 (8/25)。第二行是这个初始化为0的 vector v在五个iteration后学习到的东西。每一组vector都代表了相应support image中对于当前task有用的feature,背景和无用信息被忽略 (亮度和重要性正相关)。然后我们再看看PCA告诉了我们什么信息。
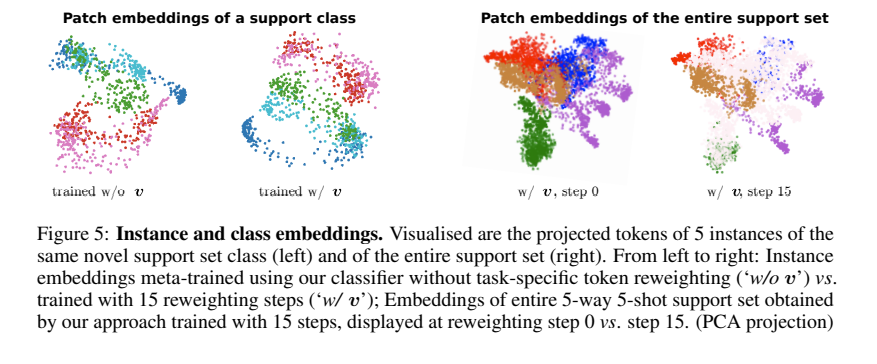
PCA
PCA显示,在叠加了vector v之后,中间重叠的embedding (entangled的信息,例如相同的背景)被忽略,每一个不同的entity更加清晰!这也验证了我们之前的假设。这些可视化相当有趣。
缺点
缺点的话,那就是需要很多gpu进行预训练。我们使用了8个A100在mini/tiered ImageNet上面进行iBot的预训练 (Thanks to Markus and unimelb, lol)。还一点是,我们需要在测试的过程fine tune我们的vector v,虽然不怎么吃资源,但是相对于不需要在测试更新的模型来说还是会慢一些。我们在此问题上也做了相应的ablation study。这篇工作的代码已开源,我们会陆续的把预训练的模型和训练过的模型上传。
未来工作与方向
2022相对于2019来说小样本图像分类趋于饱和,大家可能发现了目前大框架下模型的上限 (pretraing+fine tuning),大家都在为提升几个点焦头烂额 (也包括我)。但是我们希望,越来越多的人可以尝试在ViT下的小样本图像分类。进一步探索ViT的adaptability。很多人说小样本学习是学术界的自嗨,可能有一定的道理。但是小样本学习的关键和本质是efficient adaptation,我相信解决此问题是真正AI纪元到来前必经的一步。希望同领域的学者能够做出更多更优秀的工作,本人在此献上最真诚的祝福。太瞌睡了,可能有很多语法错误,请大家谅解。
(Want to know more? Check our paper here)
← Back to blog